Backends
In this page, we list our available implementations for standard attention (FMHA), and neighborhood attention (FNA).
Note on torch.compile support
Starting in version 0.21.5, NATTEN offers full support for torch.compile.
However, this has only been verified for torch >= 2.8.
Use torch.compile in earlier versions at your own risk.
CUTLASS FNA / FMHA
Supported features
- Inference (forward pass)
- Training (backward pass)
- GQA/MQA support (with tensor repeats)
- MLA support (head_dim != head_dim_v)
- torch.compile support without graph breaks
FMHA-specific features
- Causal masking
- Variable length with sequence-packed format
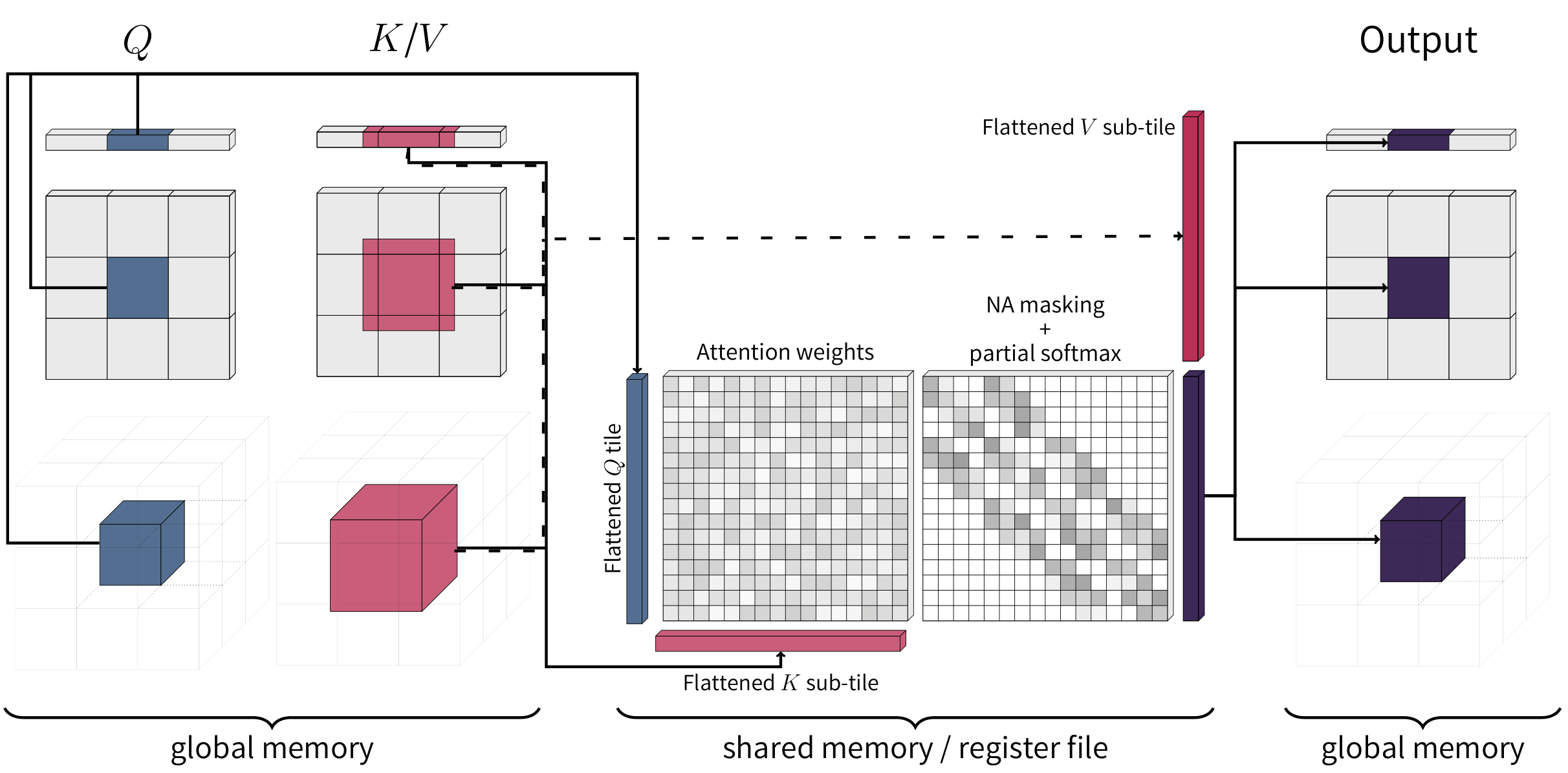
Visualization of FNA, as proposed in Faster Neighborhood Attention (2024).
Based on xFormers FMHA (a.k.a. memory-efficient attention), this kernel is based on the CUTLASS 2.X API, and targets multiple architectures: SM50 (Maxwell), SM70 (Volta), SM75 (Turing), and SM80 (Ampere). You can use these kernels on any NVIDIA GPU with compute capability >= 5.0, and both for training and inference.
Some newer architectures such as Hopper (SM90), and Blackwell DC-class (SM100, SM103) have much more performant dedicated kernels.
This implementation fuses multi-dimensional tiling directly into the kernel, but at the same time may suffer from additional overhead of software predication. To read more about this, we refer you to our Generalized Neighborhood Attention paper, in which we also proposed solutions such as Token Permutation, which we use to build our Hopper and Blackwell kernels.
Finding configurations
You can use profiler dry runs to find configurations for any of our backends, and also find backends compatible with your device and use case. You can also use the following functions in your code.
Finding configurations for CUTLASS FMHA/FNA
Returns CUTLASS FMHA configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a device with compute capability >= 5.0, and if so, returns forward pass configurations compatible with the specific compute capability, tensor dtype and head dim.
Each configuration for this operation is a tuple of two integers: (q_tile_size,kv_tile_size). These are arguments to natten.attention.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[int, int]]
|
List of tuples of two integers corresponding to query and KV tile sizes. |
Returns CUTLASS FMHA backward pass configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a device with compute capability >= 5.0, and if so, returns backward pass configurations compatible with the specific compute capability, tensor dtype and head dim.
Each configuration for this operation is a tuple of two integers: (backward_q_tile_size,backward_kv_tile_size). These are arguments to natten.attention.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[int, int]]
|
List of tuples of two integers corresponding to query and KV tile sizes in the backward pass. |
Returns CUTLASS FNA configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a device with compute capability >= 5.0, and if so, returns forward pass configurations compatible with the specific compute capability, tensor dtype and head dim, and according to the rank of the token layout (1D/2D/3D).
Each configuration for this operation is a tuple of two integer tuples: (q_tile_shape,kv_tile_shape). These are arguments to natten.na1d, natten.na2d,
and natten.na3d.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[tuple, tuple]]
|
List of tuples of two integer tuples corresponding to query and KV tile shapes. |
Returns CUTLASS FNA backward pass configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a device with compute capability >= 5.0, and if so, returns backward pass configurations compatible with the specific compute capability, tensor dtype and head dim.
Each configuration for this operation is a tuple of two integers: (backward_q_tile_shape,backward_kv_tile_shape). These are arguments to natten.na1d,
natten.na2d, and natten.na3d.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[tuple, tuple]]
|
List of tuples of two integer tuples corresponding to query and KV tile shapes in the backward pass. |
Hopper FNA / FMHA
Supported features
- Inference (forward pass)
- Training (backward pass)
- GQA/MQA support (with tensor repeats)
- MLA support (head_dim != head_dim_v)
- torch.compile support without graph breaks
FMHA-specific features
- Causal masking
- Variable length with sequence-packed format
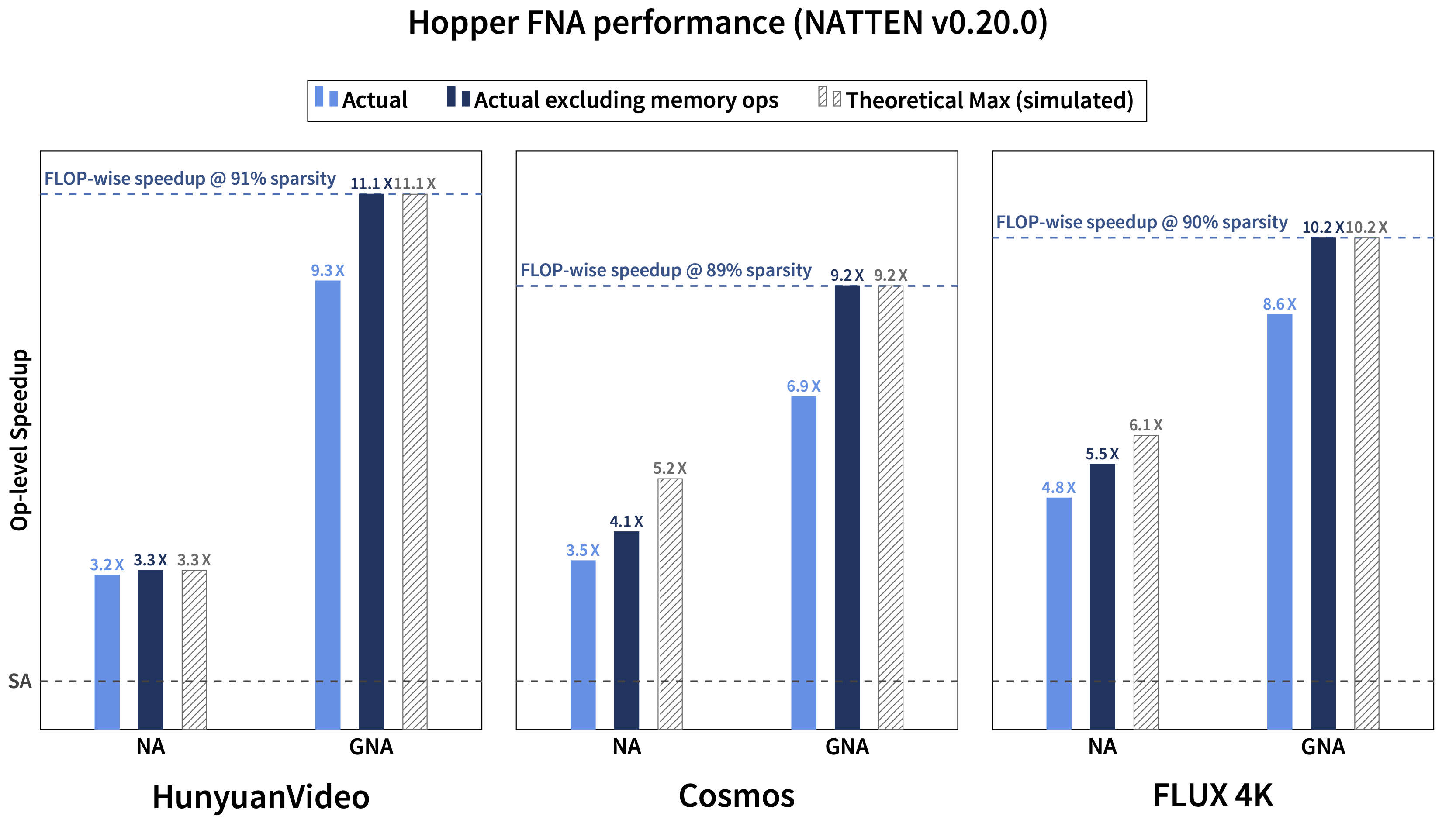
Performance levels of Hopper FNA (forward pass) as of version 0.20.0.
Based on CUTLASS's Hopper FMHA kernel (3.X API), this backend offers non-persistent, warp-specialized cooperative, and warp-specialized ping-ponging kernels, similar to Flash Attention 3. This kernel exhibits similar forward pass (inference) performance to Flash Attention 3. Backward pass is more limited compared to Flash Attention 3 and cuDNN's Hopper FMHA for now, but we plan to improve the performance to those levels in future releases.
This backend does not fuse multi-dimensional tiling into the kernel, and instead uses Token Permutation.
Finding configurations
You can use profiler dry runs to find configurations for any of our backends, and also find backends compatible with your device and use case. You can also use the following functions in your code.
Finding configurations for Hopper FMHA/FNA
Returns Hopper FMHA configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a Hopper GPU (SM90; compute capability 9.0), and if so, returns forward pass configurations compatible with the tensor dtype and head dim.
Each configuration for this operation is a tuple of one integer tuple, and another integer:
((q_tile_size, kv_tile_size), kernel_schedule). These are arguments to
natten.attention.
kernel_schedule is specific to Hopper FNA/FMHA only.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[Tuple[int, int], KernelSchedule]]
|
List of tuples of one tuple of two integers corresponding to query and KV tile sizes, and a kernel schedule enum type. |
Returns Hopper FMHA backward pass configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a Hopper GPU (SM90; compute capability 9.0), and if so, returns backward pass configurations compatible with the tensor dtype and head dim.
Each configuration for this operation is an integer tuple:
(backward_q_tile_size, backward_kv_tile_size). These are arguments to
natten.attention.
Note that unlike forward pass, kernel schedule is not part of the configuration. All backward pass kernels are persistent warp-specialized. See CUTLASS's example 88 for more.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[int, int]]
|
List of integer tuples corresponding to query and KV tile sizes. |
Returns Hopper FNA configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a Hopper GPU (SM90; compute capability 9.0), and if so, returns forward pass configurations compatible with the tensor dtype and head dim.
Each configuration for this operation is a tuple of one tuple, and another integer:
((q_tile_shape, kv_tile_shape), kernel_schedule). These are arguments to
natten.na1d, natten.na2d, and natten.na3d.
kernel_schedule is specific to Hopper FNA/FMHA only.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[Tuple[tuple, tuple], KernelSchedule]]
|
List of tuples of one tuple of two shape tuples, corresponding to query and KV tile shapes, and a kernel schedule enum type. |
Returns Hopper FNA backward pass configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a Hopper GPU (SM90; compute capability 9.0), and if so, returns backward pass configurations compatible with the tensor dtype and head dim.
Each configuration for this operation is a tuple of two tuples:
(q_tile_shape, kv_tile_shape). These are arguments to natten.na1d,
natten.na2d, and natten.na3d.
Note that unlike forward pass, kernel schedule is not part of the configuration. All backward pass kernels are persistent warp-specialized. See CUTLASS's example 88 for more.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[tuple, tuple]]
|
List of tuples of two shape tuples, corresponding to query and |
List[CutlassHopperFnaBackwardConfigType]
|
KV tile shapes. |
Blackwell FNA / FMHA
Supported features
- Inference (forward pass)
- Training (backward pass)
- GQA/MQA support (with tensor repeats)
- MLA support (head_dim != head_dim_v)
- torch.compile support without graph breaks
FMHA-specific features
- Causal masking
- Variable length with sequence-packed format
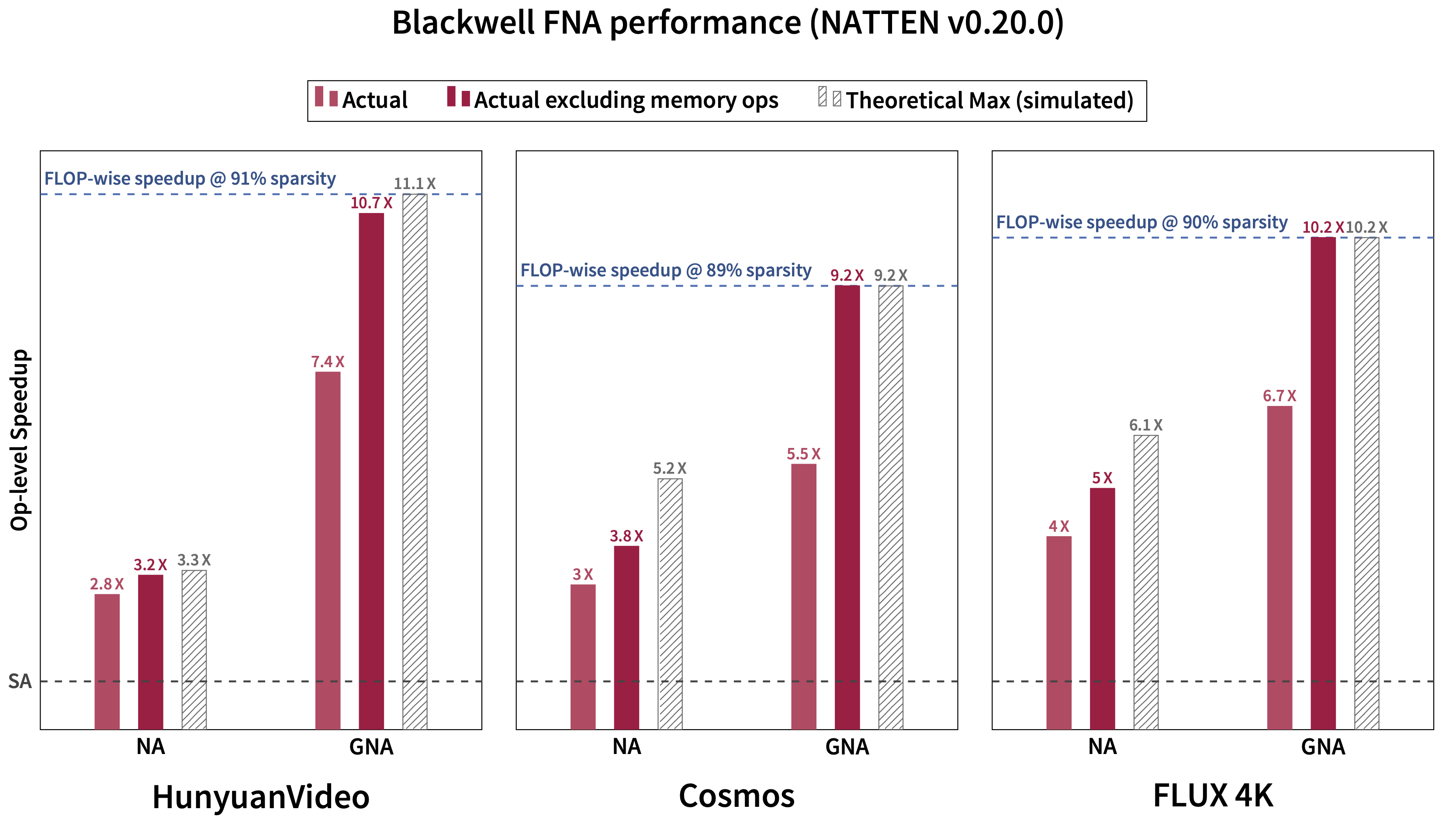
Performance levels of Blackwell FNA (forward pass) as of version 0.20.0 (also
reported in
Generalized Neighborhood Attention (2025)).
Based on CUTLASS's Blackwell FMHA kernel (3.X API), this backend offers incredible forward pass and backward pass performance, which is comparable with cuDNN's Blackwell FMHA.
This backend does not fuse multi-dimensional tiling into the kernel, and instead uses Token Permutation.
Finding configurations
You can use profiler dry runs to find configurations for any of our backends, and also find backends compatible with your device and use case. You can also use the following functions in your code.
Finding configurations for Blackwell FMHA/FNA
Returns Blackwell FMHA configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a Blackwell datacenter GPU (SM100; compute capability 10.0), and if so, returns forward pass configurations compatible with the tensor dtype and head dim.
Each configuration for this operation is a tuple of two integers: (q_tile_size,kv_tile_size). These are arguments to natten.attention.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[int, int]]
|
List of tuples of two integers corresponding to query and KV tile sizes. |
Returns Blackwell FMHA backward pass configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a Blackwell datacenter GPU (SM100; compute capability 10.0), and if so, returns backward pass configurations compatible with the tensor dtype and head dim.
Each configuration for this operation is a tuple of two integers: (q_tile_size,kv_tile_size). These are arguments to natten.attention.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[int, int]]
|
List of tuples of two integers corresponding to query and KV tile sizes. |
Returns Blackwell FNA configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a Blackwell datacenter GPU (SM100; compute capability 10.0), and if so, returns forward pass configurations compatible with the tensor dtype and head dim, and according to the rank of the token layout (1D/2D/3D).
Each configuration for this operation is a tuple of two integer tuples: (q_tile_shape,kv_tile_shape). These are arguments to natten.na1d, natten.na2d,
and natten.na3d.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[tuple, tuple]]
|
List of tuples of two integer tuples corresponding to query and KV tile shapes. |
Returns Blackwell FNA backward pass configurations compatible with input tensors, if any.
Checks first if a CUDA tensor, and on a Blackwell datacenter GPU (SM100; compute capability 10.0), and if so, returns backward pass configurations compatible with the tensor dtype and head dim, and according to the rank of the token layout (1D/2D/3D).
Each configuration for this operation is a tuple of two integer tuples: (q_tile_shape,kv_tile_shape). These are arguments to natten.na1d, natten.na2d,
and natten.na3d.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
Returns:
| Type | Description |
|---|---|
List[Tuple[tuple, tuple]]
|
List of tuples of two integer tuples corresponding to query and KV tile shapes. |
Flex FNA / FMHA
Warning
This backend is experimental.
Info
This backend requires PyTorch >= 2.7.
Supported features
- Inference (forward pass)
- Training (backward pass)
- GQA/MQA support (with tensor repeats)
- MLA support (head_dim != head_dim_v)
- torch.compile support without graph breaks
FMHA-specific features
- Causal masking
- Variable length with sequence-packed format
This backend is PyTorch-native, and supports some non-NVIDIA devices as well (CPU and ROCm). It is based on Flex Attention.
Since this backend is implemented in PyTorch, fusion of multi-dimensional tiling is not possible. This backend however does support Token Permutation, similar to the Hopper and Blackwell backends.
By default, if tile shapes are not specified, token permutation will be disabled, and our legacy Flex mask will be used. If tile shapes are specified, it will use token permutation.
Finding configurations
You can use profiler dry runs to find configurations for any of our backends, and also find backends compatible with your device and use case. You can also use the following functions in your code.
Finding configurations for Flex FMHA/FNA
Returns Flex FMHA configurations compatible with input tensors, if any.
Each configuration for this operation is a tuple of two integers: (q_tile_size,kv_tile_size). These are arguments to natten.attention.
Not specifying these arguments while backend is Flex will default to q_tile_size = 64 and
kv_tile_size = 64.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
torch_compile
|
bool
|
Whether or not you intend to use compiled block mask and flex attention kernel. |
False
|
Returns:
| Type | Description |
|---|---|
List[Tuple[int, int]]
|
List of tuples of two integers corresponding to query and KV tile sizes. |
Returns Flex FNA configurations compatible with input tensors, if any.
Each configuration for this operation is a tuple of two integer tuples: (q_tile_shape,kv_tile_shape). These are arguments to natten.na1d, natten.na2d,
and natten.na3d.
Not specifying these arguments while backend is Flex will default to single-dimensional tiling,
and will not use our Token Permutation approach. By explicitly specifying tile shapes, you will
automatically use our Token Permutation approach, which saves you the most compute.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
query
|
Tensor
|
Query tensor matching the shape, dtype, and device of your use case. |
required |
key
|
Tensor
|
Key tensor matching the shape, dtype, and device of your use case. |
required |
value
|
Tensor
|
Value tensor matching the shape, dtype, and device of your use case. |
required |
torch_compile
|
bool
|
Whether or not you intend to use compiled block mask and flex attention kernel. |
False
|
Returns:
| Type | Description |
|---|---|
List[Tuple[tuple, tuple]]
|
List of tuples of two integer tuples corresponding to query and KV tile shapes. |